How to Choose the Right GPU
1.主流GPU分类

第一档, A或H, A800, H800运算性能没砍, 显存带宽80%
第二档, L是H的30-50%, 是A系列降级. 如果预算在4090之上又不到A
第三档, RTX
T不推荐
2.主流GPU性能和性价比
性能
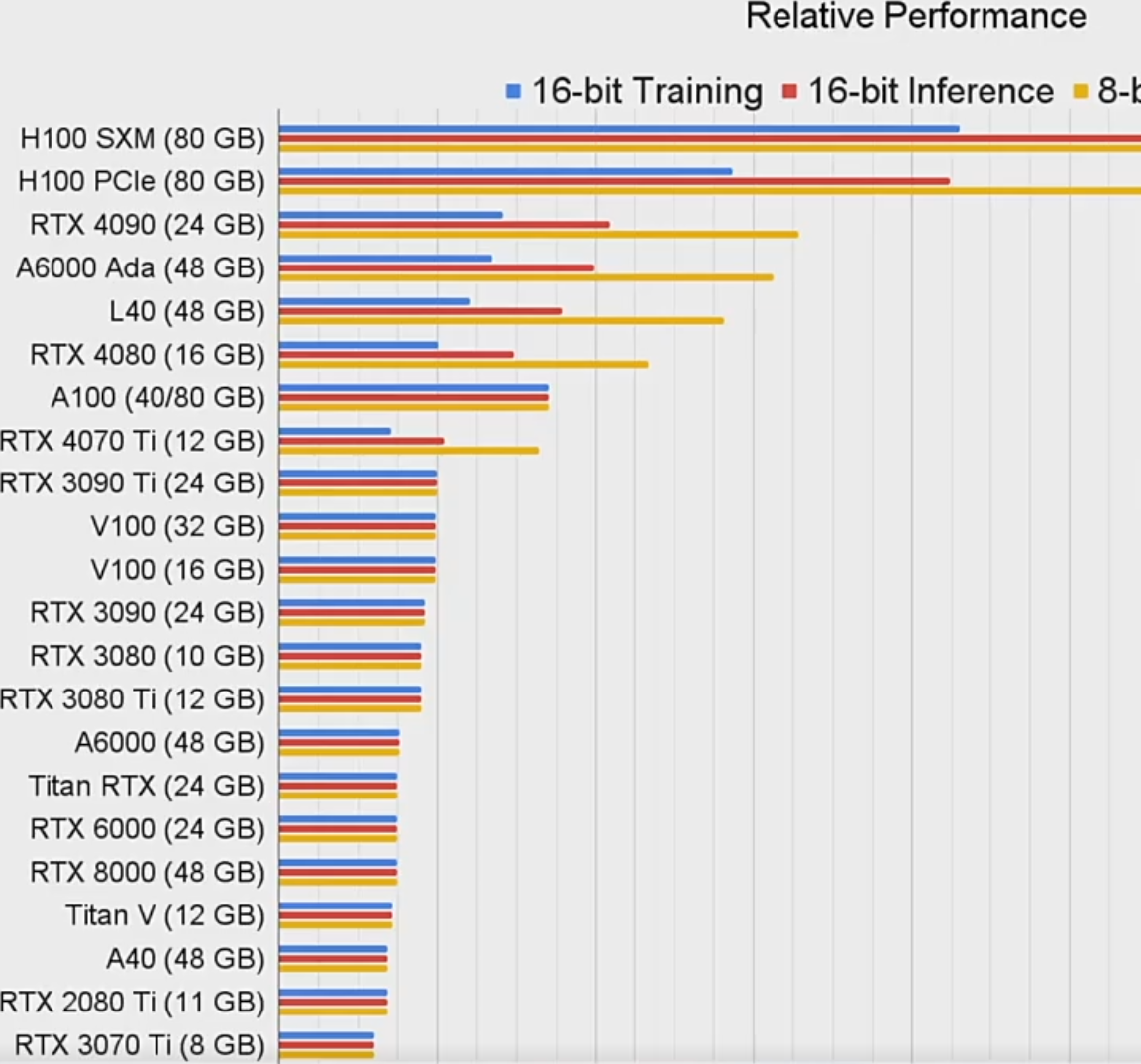
A系列适合训练不适合推理
我们以 RTX 4090 为例,它的推理能力非常强,但训练性能相对较弱。刚才我们做了简单对比,大家应该也能看出来:如果你的应用场景以推理为主,那么 4090 是非常合适的选择。
但如果是用于训练的场景,4090 的性能就没那么出色了。虽然它的价格可能只是 A100 的十分之一,甚至更低,但它只有 24GB 的显存,而 A100 提供了 40GB 或 80GB。因此,如果你希望达到和 A100 相同的显存水平,可能需要多张 4090 组成一个集群。
然而,多个 4090 组成集群后,显卡之间的信息传输效率会有所下降。即使搭建了这样的集群,其训练效率可能仍然不如一张 A100 高效。
在训练性能方面,如果你不急于完成训练任务,4090 是一个性价比很高的选择;但如果预算充足,直接选择 A100 无疑是更好的方案。
当然,如果你的模型只需要 5GB、6GB 或 10GB 左右的显存,那么使用双卡 3090 或四卡 3090 也是不错的选择。
性价比
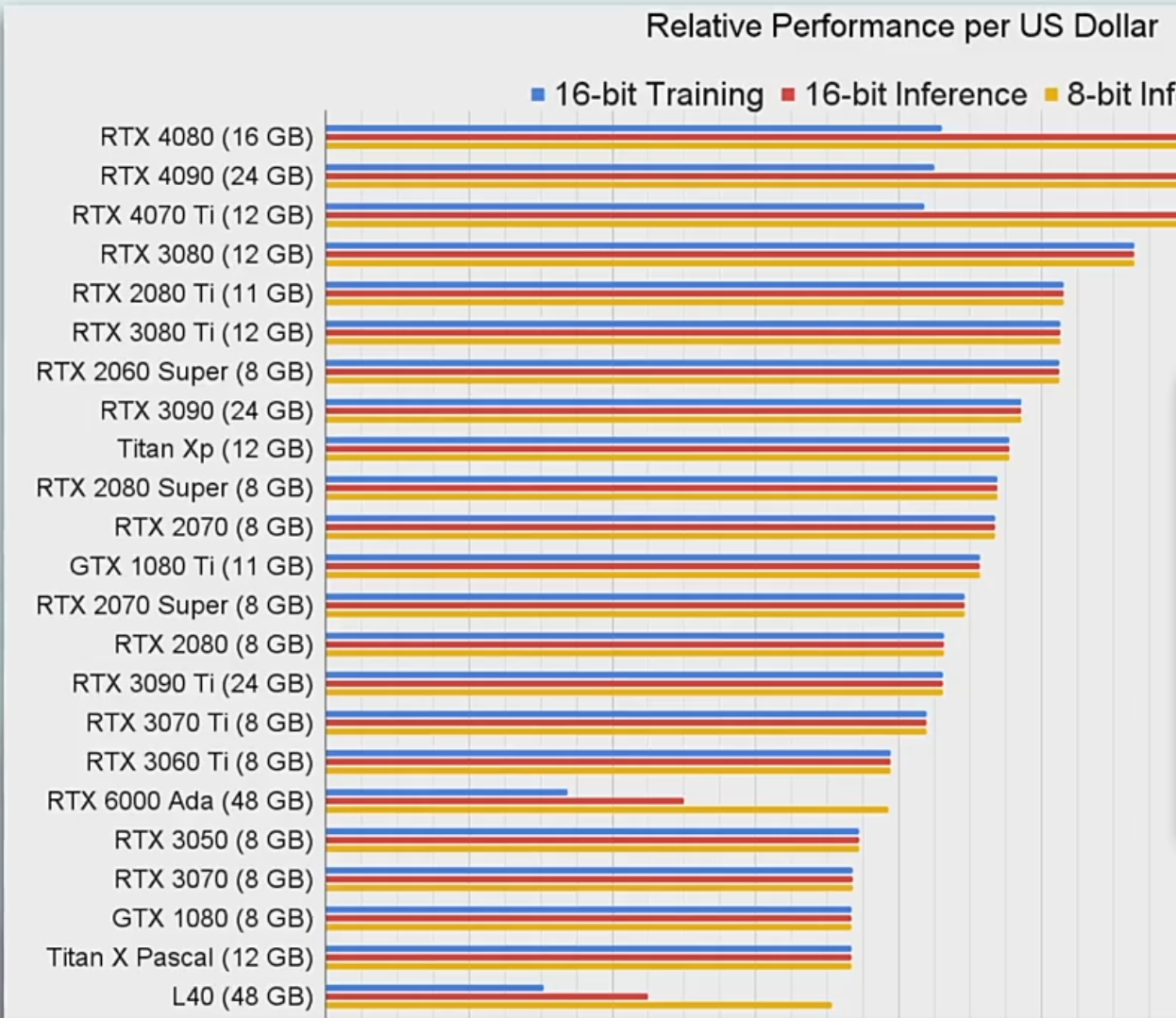
在这里我们还没有把显存等因素,以及多卡组成集群所带来的性能损耗考虑进去。我们只关注一个核心问题:在单卡场景下,单位价格所能买到的显卡性能排名如何。
从这个角度来看,RTX 4080无疑是最具性价比的一款。如果你的应用属于小规模的深度学习训练,或者是小模型的推理任务,4080 完全可以胜任,性价比非常高。
当然,如果你的场景是大规模集群训练,那 A100 和 H100 显然仍然是首选。
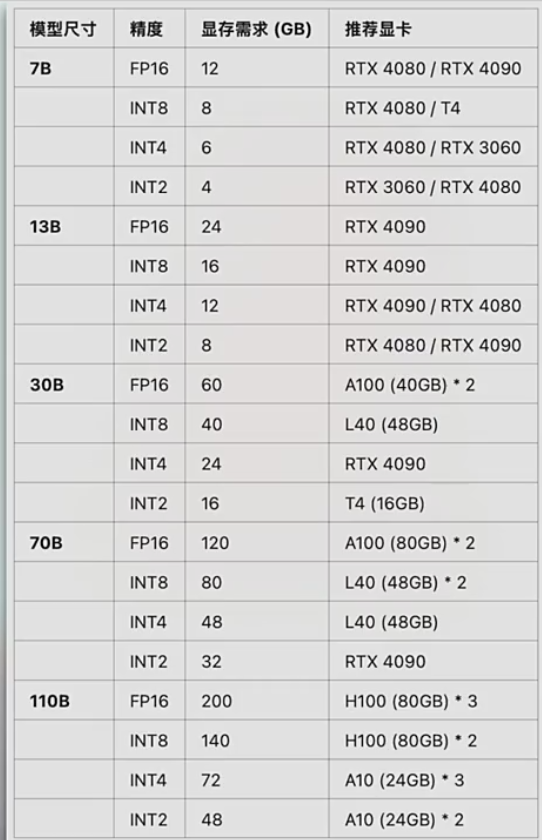
3.各类大模型显存占用和推荐配置
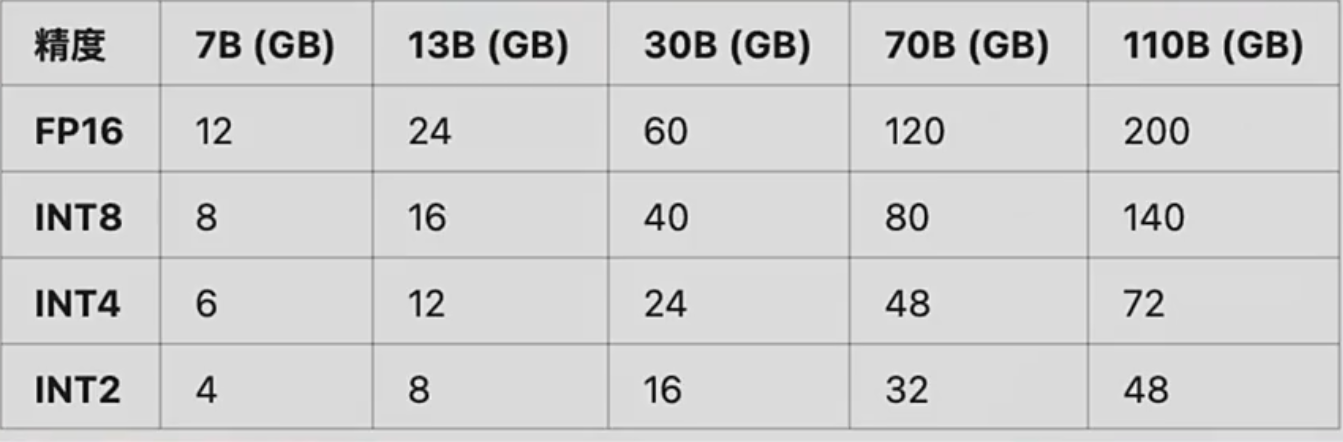
运行/推理
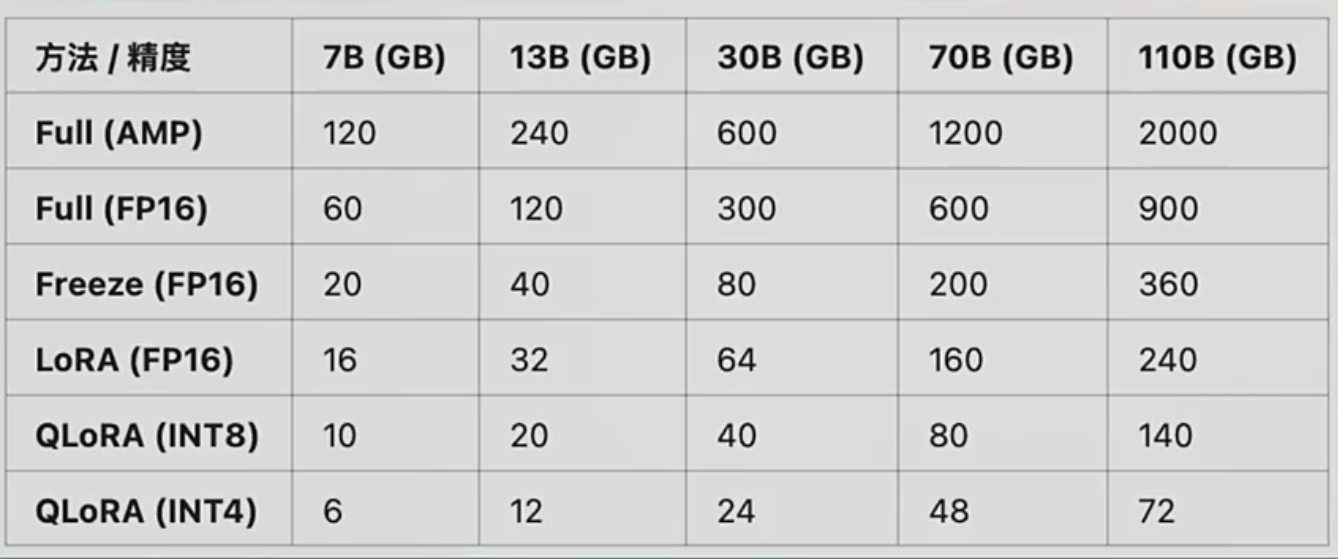
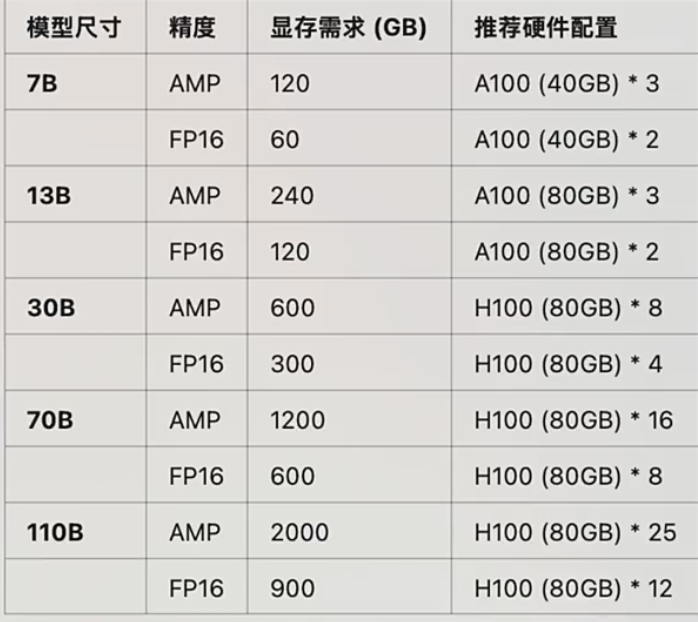
训练/微调
注意: 以下GPU的选用, 4090可以替换3090, A100替换A800, L40替换为L20
推荐推理GPU
推荐训练GPU
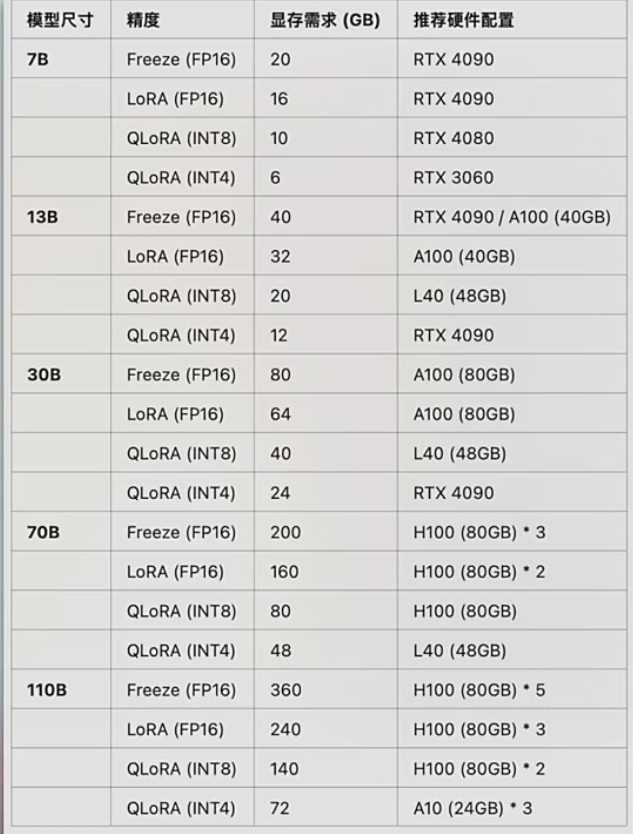
高效微调GPU
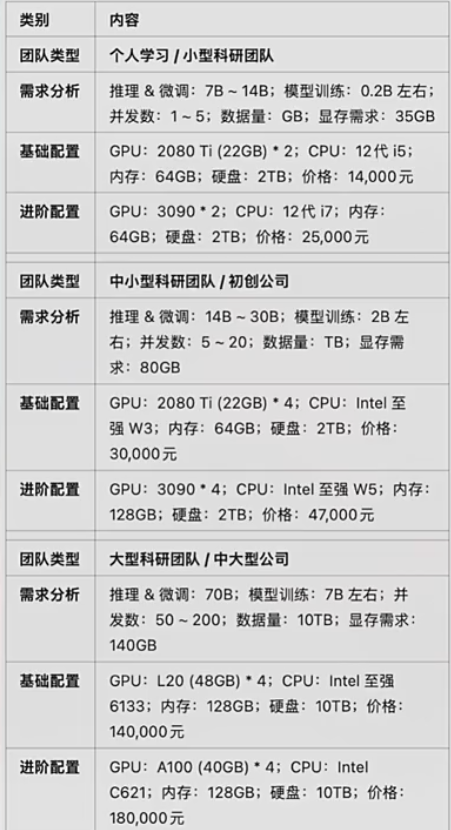
4.不同使用场景下推荐GPU配置
5.GPU理论补充与对比
基础数据

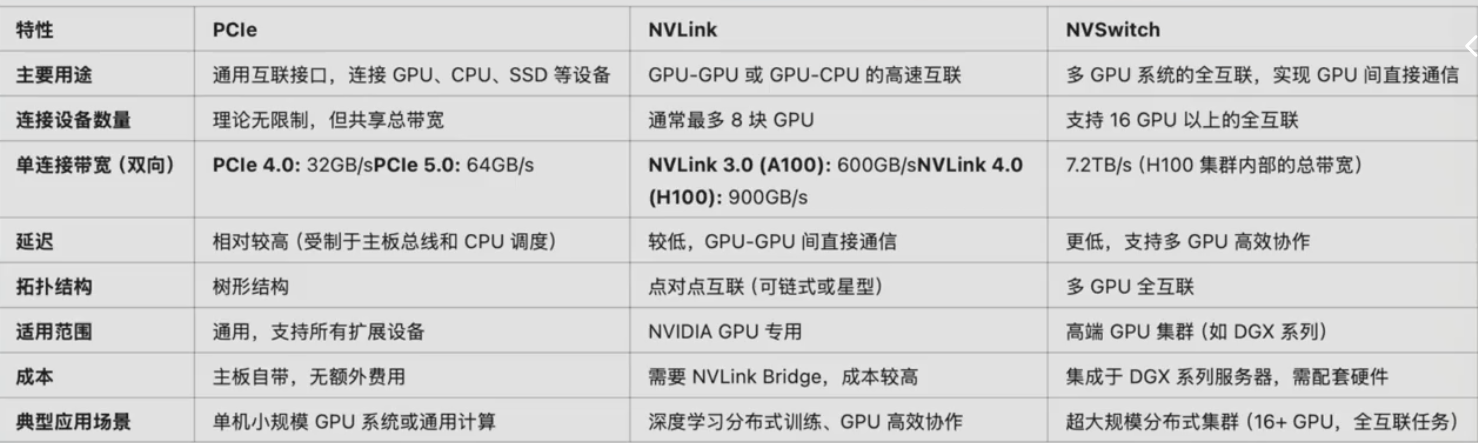
目前对于英伟达来说,从 RTX 30 系列开始,其民用级显卡已不再配备 NVLink 技术。这主要是因为在实际应用中,很少有人使用 RTX 30 系列显卡(例如 3070 或 3080)进行多卡服务器组建。
即使是使用 3090 或 4090 这样的高端消费级显卡组建多卡服务器,也无需担心缺少 NVLink,因为我们可以通过主板上的 PCIe(Peripheral Component Interconnect Express) 通道来实现高速数据交换。这种方式可以视作 NVLink 的一种替代方案。
换句话说,如果你打算用两张 3090、四张 3090,或者两张 4090 来搭建一台多卡的服务器,用于模型推理或训练,只要主板的 PCIe 插槽数量和带宽足够,就完全可以胜任,不需要 NVLink 的支持。
你只需关注主板支持的 PCIe 插槽数量,以及其版本(如 PCIe 4.0 或 5.0)。不过需要说明的是,RTX 30 和 RTX 40 系列显卡本身的内部带宽就有上限,通常达不到 PCIe 4.0(理论上每通道 16GB/s,总计 32GB/s)的最大传输速度。
也就是说,即使主板支持 PCIe 4.0 或 5.0,其带宽仍然高于显卡本身的数据处理能力,所以 PCIe 的性能已经足够使用,不存在性能瓶颈问题。
那 NVLink 现在主要用在哪里呢?它主要用于 数据中心级显卡,如 A100 或更高端的 A100G 系列。这些显卡在高性能训练任务中对多卡之间的数据交换速度要求非常高,NVLink 提供了一种显卡之间直接高速互连的方案。
进一步来说,英伟达还推出了更高级的互连技术——NVSwitch。NVLink 是用于两个 GPU 之间的点对点连接,而 NVSwitch 则是用于多个 GPU 间的全互联架构,支持多路 GPU 高速互通。目前 H100 及以上型号的英伟达 GPU 已经支持 NVSwitch,内部传输带宽高达 7.2 TB/s,远远超过 NVLink,是数据中心级 AI 集群的关键组件。
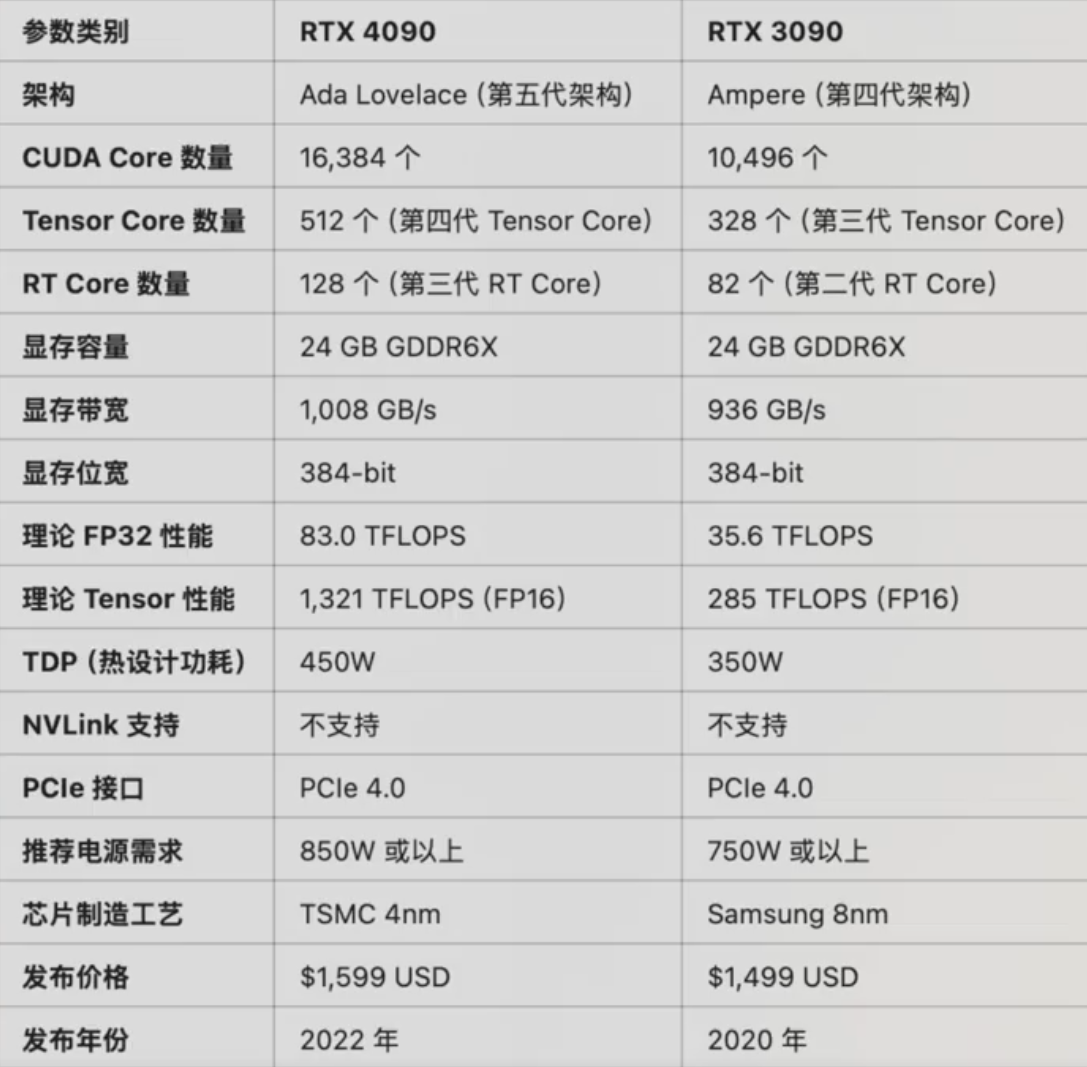
3090VS4090
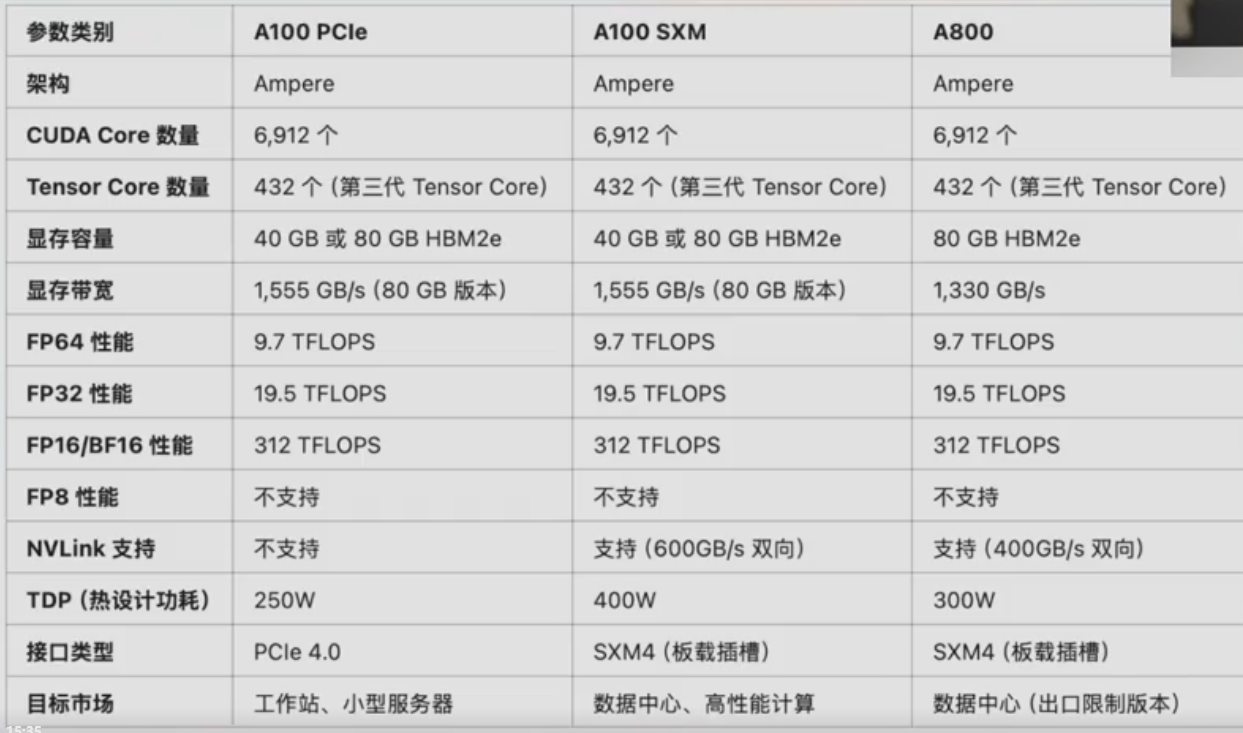
A100VSA800
References
大量参考赋范空间: https://kq4b3vgg5b.feishu.cn/wiki/JuJSwfbwmiwvbqkiQ7LcN1N1nhd